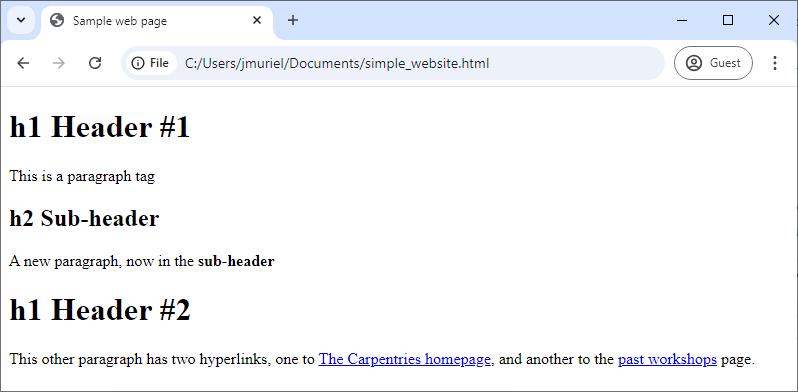
Image 1 of 1: ‘An anatomical breakdown of a URL string, labeling its components: protocol (http), host ([www.domain.com](https://www.domain.com/)), port (1234), resource path (/path/to/resource), and query (?a=b&x=y)’
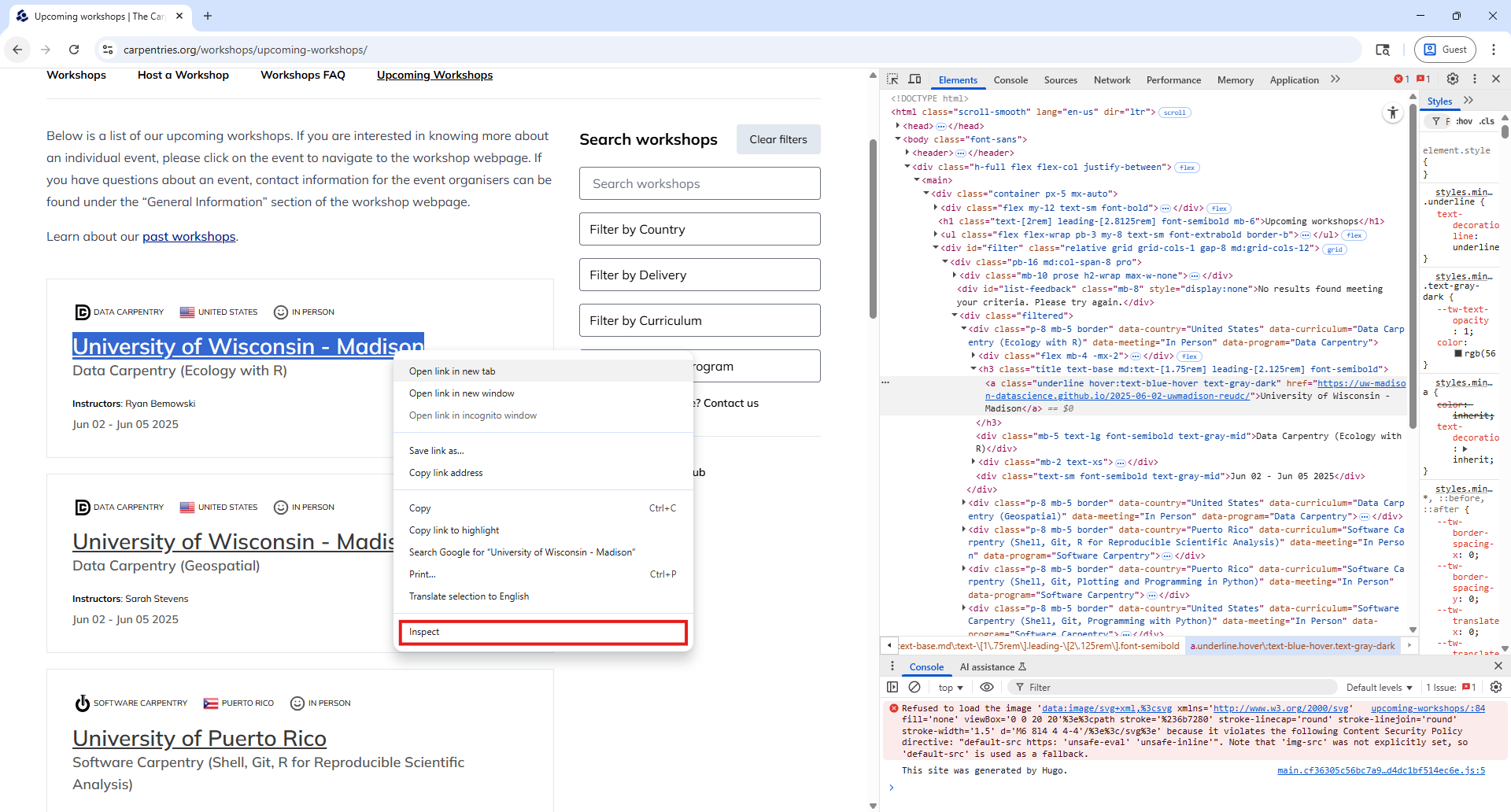
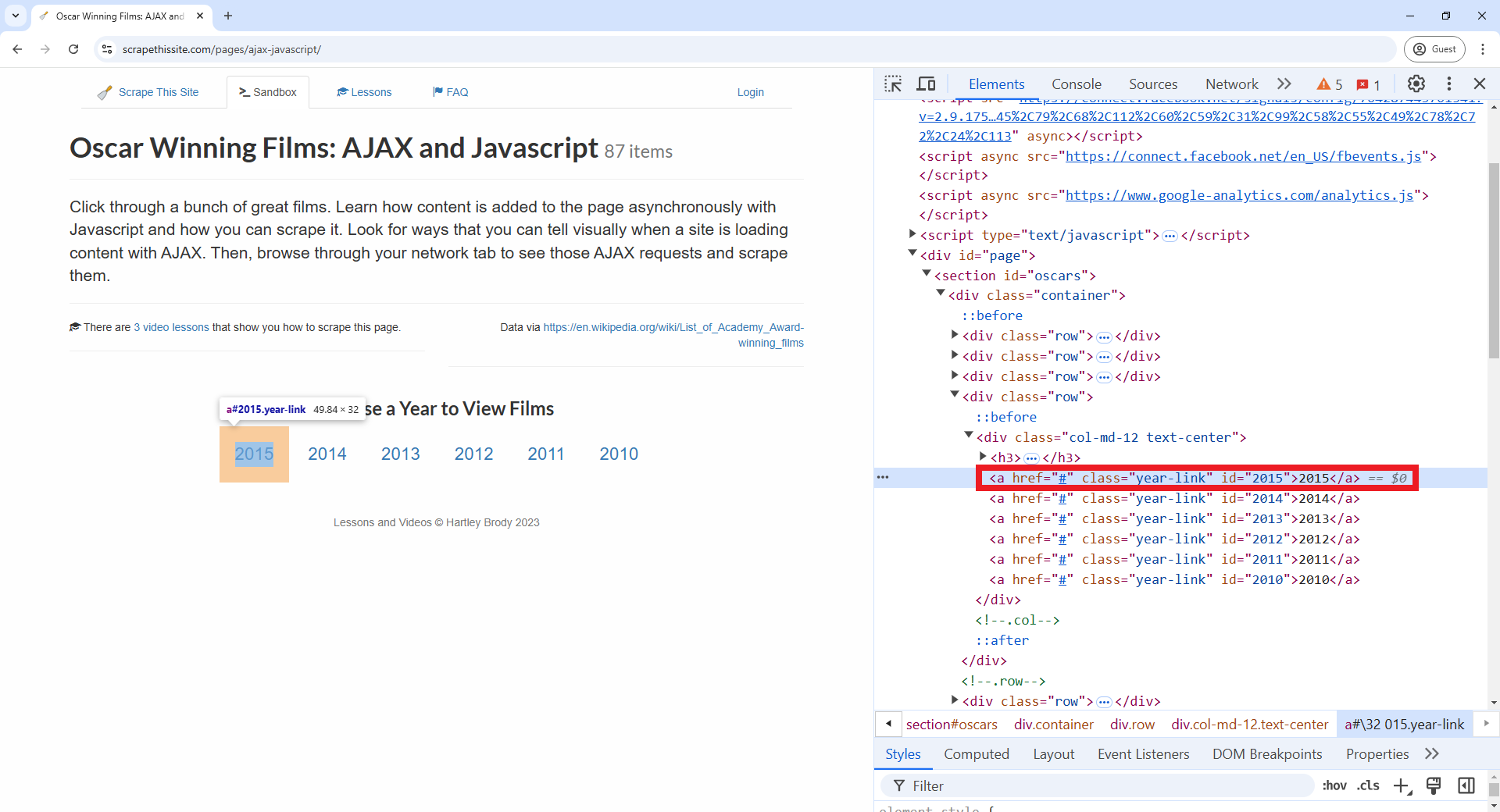
Image 1 of 1: ‘A diagram showing the HTTP request-response cycle between a client computer and a server, highlighting the URL + Verb request and the Status Code + Message Body response’
), port (1234), resource path (/path/to/resource), and query (?a=b&x=y)](fig/http1-url-structure.png)