Dynamic websites
Last updated on 2026-01-15 | Edit this page
Estimated time: 35 minutes
Overview
Questions
- What are the differences between static and dynamic websites?
- Why is it important to understand these differences when doing web scraping?
- How can I start my own web scraping project?
Objectives
- Use the
Seleniumpackage to scrape dynamic websites. - Understand the usual pipeline of a web scraping project.
Visit this practice webpage created by Hartley Brody for learning and practicing web scraping: https://www.scrapethissite.com/pages/ajax-javascript/ (but first, read the terms of use). Select “2015” to display that year’s Oscar-winning films. Now try viewing the HTML behind the page, either using the View Page Source tool in your browser or by using Python with the requests and BeautifulSoup packages, as we’ve learned.
Can you find the Best Picture winner Spotlight anywhere in the HTML? Can you find any of the other movies or the data from the table? If not, how could you scrape this page?
When you explore a page like this, you’ll notice that the movie data (including the title Spotlight) isn’t present in the initial HTML source. That’s because the website uses JavaScript to load the information dynamically. JavaScript is a programming language that runs in your browser and allows websites to fetch, process, and display content on the fly — often in response to user actions, like clicking a button.
When you select “2015”, your browser runs JavaScript (triggered by
one of the <script> elements in the HTML) to retrieve
the relevant movie information from the web server and dynamically
update the table. This makes the page feel more interactive, but it also
means that the initial HTML you see doesn’t contain the movie data
itself.
You can observe this difference when using the “View page source” and “Inspect” tools in your browser: “View page source” shows the original HTML sent by the server, before any JavaScript runs. “Inspect” shows the rendered HTML, after JavaScript has executed and updated the page content.
Because the requests package only retrieves the original source HTML,
it won’t work for scraping pages like this. To scrape content that is
generated dynamically by JavaScript, we’ll use a different tool: the
Selenium package.
Using Selenium to scrape dynamic websites
Selenium is an open-source project for web browser automation. It’s especially useful for scraping tasks because it behaves like a real user interacting with a web page in a browser.
With Selenium, the browser actually renders the page, allowing JavaScript to run and load any dynamic content. This means we can access the fully loaded HTML (just like we’d see using the “Inspect” tool) after JavaScript has executed.
In addition, Selenium can simulate real user interactions like filling in text boxes, clicking buttons, scrolling, or selecting items from drop-down menus. These features are essential when scraping dynamic websites.
To get started, we’ll load the webdriver and
By components from the selenium package:
webdriverlets us launch or simulate a web browser and interact with it through code.Byhelps us specify how we want to locate elements in the HTML, by tag name (By.TAG_NAME), class (By.CLASS_NAME), ID (By.ID), name (By.NAME), and more.
We’ll also continue using the other packages introduced in the previous episode.
PYTHON
# Loading libraries
from bs4 import BeautifulSoup
import pandas as pd
from time import sleep
from selenium import webdriver
from selenium.webdriver.common.by import BySelenium can simulate different browsers like Chrome, Firefox, Safari, and others. For now, we’ll use Chrome. When you run the following line of code, a new Google Chrome window will open. Don’t close it, this is the browser that Selenium is controlling to interact with the webpage.
Later in the lesson, we’ll learn how to run headless browser
sessions. Headless means the browser runs in the background without
opening a visible window or user interface, which is useful for
automation tasks and running scripts on servers. To direct the browser
to the Oscar winners page, use the .get() method on the
driver object we just created.
PYTHON
# Open a Chrome web browser driven by Selenium
driver = webdriver.Chrome()
# Go to a specific website
driver.get("https://www.scrapethissite.com/pages/ajax-javascript/")How can we direct Selenium to click the “2015” text so the table for
that year appears? First, we need to locate that element, similar to how
we used .find() and .find_all() with
BeautifulSoup. In Selenium, we use .find_element() to get
the first matching element, and .find_elements() to get all
matches. However, the syntax for specifying search parameters is
slightly different.
For example:
To select the first
<table>element, you’d use:driver.find_element(by=By.TAG_NAME, value="table")To find a row with
<tr class="film">, you’d use:driver.find_element(by=By.CLASS_NAME, value="film")
To find the specific element that triggers the display of 2015’s Oscar winners, use the “Inspect” tool in Chrome. Right-click on the “2015” text and choose “Inspect.” In the DevTools panel, you’ll see this HTML element:
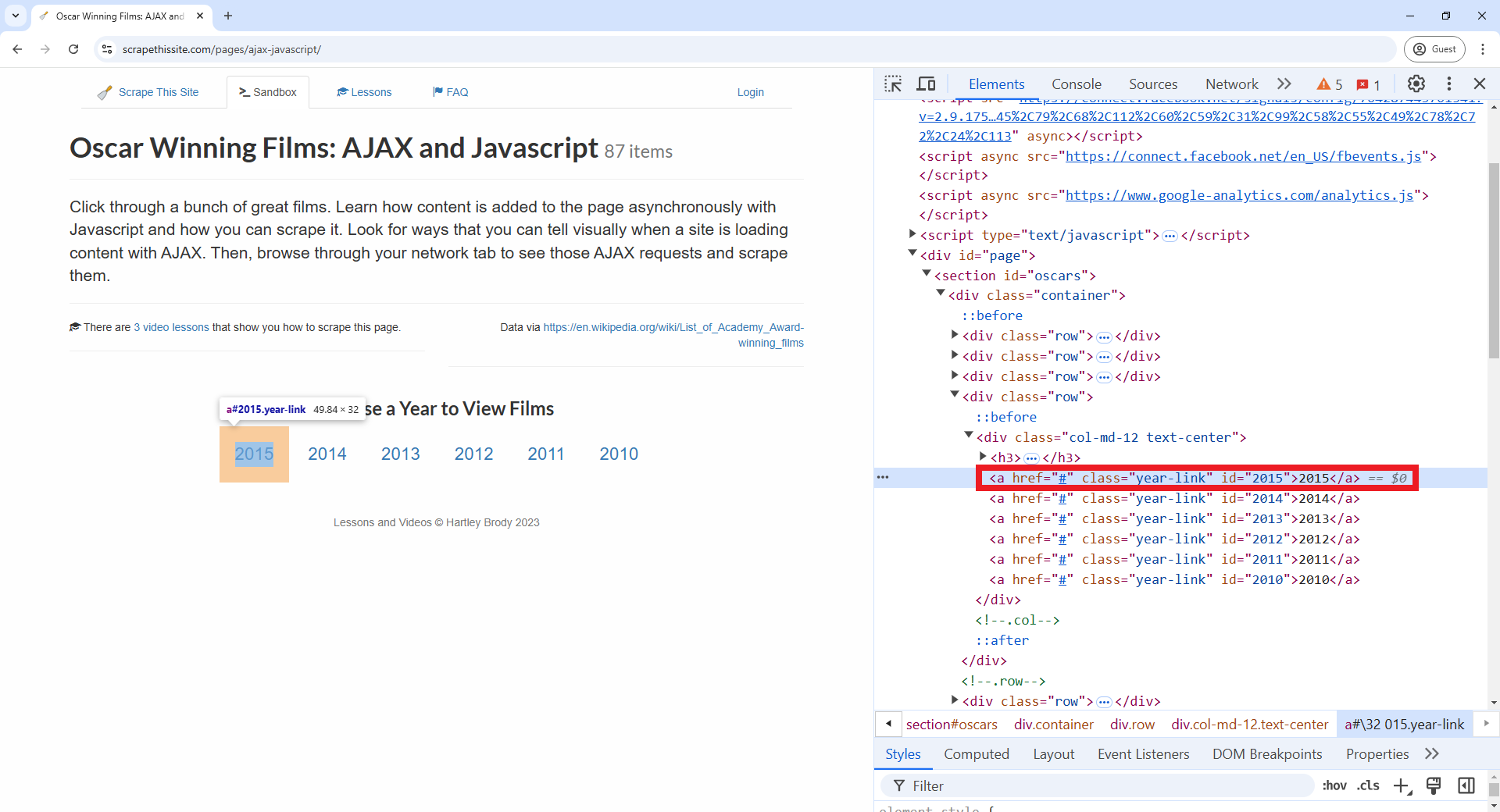
Because the id attribute is unique, we can select this
element directly using:
We’ve located the hyperlink element we need to click to display the
table for that year, and we’ll use the .click() method to
interact with it. Since the table takes a couple of seconds to load,
we’ll use the sleep() function to pause while the
JavaScript runs and the table loads. Next, we’ll use driver.page_source
to retrieve the updated HTML content from the website and store it in a
variable called html_2015. Finally, we’ll close the browser
window Selenium opened using driver.quit().
PYTHON
# Click 2015 button
button_2015.click()
# Wait for table to load
sleep(3)
# Retrieve page HTML
html_2015 = driver.page_source
# Close web browser
driver.quit()Importantly, the HTML document we stored in html_2015
is the HTML after the dynamic content loaded. This
content wasn’t present in the original HTML and wouldn’t be accessible
if we had used the requests package alone.
While we could continue using Selenium’s .find_element()
and .find_elements() methods to extract the data, we’ll
switch back to BeautifulSoup to parse the HTML and locate elements,
since we already have practice with it. For example, if we search for
the first element with the class attribute “film” and retrieve its text,
we’ll see that the HTML now includes the movie “Spotlight.”
PYTHON
# Parse HTML and
soup = BeautifulSoup(html_2015, 'html.parser')
print(soup.find(class_='film').prettify())OUTPUT
<tr class="film">
<td class="film-title">
Spotlight
</td>
<td class="film-nominations">
6
</td>
<td class="film-awards">
2
</td>
<td class="film-best-picture">
<i class="glyphicon glyphicon-flag">
</i>
</td>
</tr>The following code repeats the process of clicking and loading the 2015 data, but now in “headless” mode (meaning the browser runs in the background without opening a visible window). After the data loads, the code extracts information from the table one column at a time, using the fact that each column has a unique class attribute. Instead of writing traditional for loops to extract the text from each element returned by .find_all(), we use list comprehensions, which provide a more concise way to generate lists. You can learn more about them reading Python’s documentation on list comprehensions or this short tutorial by Programiz.
PYTHON
# Create the Selenium webdriver and make it headless
options = webdriver.ChromeOptions()
options.add_argument("--headless=new")
driver = webdriver.Chrome(options=options)
# Load the website. Find and click 2015. Get post JavaScript execution HTML. Close webdriver
driver.get("https://www.scrapethissite.com/pages/ajax-javascript/")
button_2015 = driver.find_element(by=By.ID, value="2015")
button_2015.click()
sleep(3)
html_2015 = driver.page_source
driver.quit()
# Parse HTML using BeautifulSoup and extract each column as a list of values ising list comprehensions
soup = BeautifulSoup(html_2015, 'html.parser')
titles_lc = [elem.get_text() for elem in soup.find_all(class_="film-title")]
nominations_lc = [elem.get_text() for elem in soup.find_all(class_="film-nominations")]
awards_lc = [elem.get_text() for elem in soup.find_all(class_="film-awards")]
# For the best picture column, we can't use .get_text() as there is no text
# Rather, we want to see if there is an <i> tag
best_picture_lc = ["Yes" if elem.find("i") == None else "No" for elem in soup.find_all(class_="film-best-picture")]
# Create a dataframe based on the previous lists
movies_2015 = pd.DataFrame(
{'titles': titles_lc, 'nominations': nominations_lc, 'awards': awards_lc, 'best_picture': best_picture_lc}
)Challenge
Using what we’ve learned in this episode, write a Python script that collects Oscar-winning film data for all years from 2010 to 2015 from Hartley Brody’s website. Hint: Reuse the code you wrote to scrape the 2015 data, and place it inside a loop that goes through each year.
In addition to looping through each year, the following solution changes the code by defining two functions: one that finds and clicks on a year and returns the HTML after the data loads, and another that takes this HTML, parses it, and extracts the data into a DataFrame.
To let you observe how Selenium opens the browser and interacts with the page, this version does not use the “headless” option.
PYTHON
# Function to search year hyperlink and click it
def findyear_click_gethtml(year):
button = driver.find_element(by=By.ID, value=year)
button.click()
sleep(3)
html = driver.page_source
return html
# Function to parse html, extract table data, and assign year column
def parsehtml_extractdata(html, year):
soup = BeautifulSoup(html, 'html.parser')
titles_lc = [elem.get_text() for elem in soup.find_all(class_="film-title")]
nominations_lc = [elem.get_text() for elem in soup.find_all(class_="film-nominations")]
awards_lc = [elem.get_text() for elem in soup.find_all(class_="film-awards")]
best_picture_lc = ["No" if elem.find("i") == None else "Yes" for elem in soup.find_all(class_="film-best-picture")]
movies_df = pd.DataFrame(
{'titles': titles_lc, 'nominations': nominations_lc, 'awards': awards_lc, 'best_picture': best_picture_lc, 'year': year}
)
return movies_df
# Open Selenium webdriver and go to the page
driver = webdriver.Chrome()
driver.get("https://www.scrapethissite.com/pages/ajax-javascript/")
# Create empty dataframe where we will append/concatenate the dataframes we get for each year
result_df = pd.DataFrame()
for year in ["2010", "2011", "2012", "2013", "2014", "2015"]:
html_year = findyear_click_gethtml(year)
df_year = parsehtml_extractdata(html_year, year)
result_df = pd.concat([result_df, df_year])
# Close the browser that Selenium opened
driver.quit()Challenge
If you’re ready for a break from scraping table data like we’ve done in the last two episodes, try this new exercise to practice working with dynamic websites. Visit this product page created by scrapingcourse.com and extract the name and price of each product, along with the hyperlink from each product card to its detailed view page.
Once you’ve done that, and if you’re up for an additional challenge, visit each product’s detail page and scrape its SKU, Category, and Description.
To identify the elements that contain the data you need, start by
using the “Inspect” tool in your browser. The screenshot below shows an
example from the website, where each product card is a
<div> element with several attributes that help
narrow down your search.

For instance, you can target these product cards by selecting
<div> elements with the attribute
'data-testid'='product-item'. Once you’ve found all the
relevant <div> elements, you can extract the
necessary information from each:
Hyperlink: This is the
hrefattribute of the<a>tag within each product card.Product name: This is inside a
<span>tag with the class attribute'product-name'.Price: This is also inside a
<span>tag, and we can identify it using the attribute'data-content'='product-price'.
PYTHON
# Open Selenium webdriver in headless mode and go to the desired page
options = webdriver.ChromeOptions()
options.add_argument("--headless=new")
driver = webdriver.Chrome(options=options)
driver.get("https://www.scrapingcourse.com/javascript-rendering")
# As we don't have to click anything, just wait for the JavaScript to load, we can get the HTML right away
sleep(3)
html = driver.page_source
# Parste the HTML
soup = BeautifulSoup(html, 'html.parser')
# Find all <div> elements that have a 'data-testid' attribute with the value of 'product-item'
divs = soup.find_all("div", attrs = {'data-testid': 'product-item'})
# Loop through the <div> elements we found, and for each get the href,
# the name (inside a <span> element with attribute class="product-name")
# and the price (inside a <span> element with attribute data-content="product-price"
list_of_dicts = []
for div in divs:
# Create a dictionary to store the data we want for each product
item_dict = {
'link': div.find('a')['href'],
'name': div.find('span', attrs = {'class': 'product-name'}).get_text(),
'price': div.find('span', attrs = {'data-content': 'product-price'}).get_text()
}
list_of_dicts.append(item_dict)
all_products = pd.DataFrame(list_of_dicts)We could arrive to the same result if we replace the for loop with list comprehensions. So here is another possible solution with that approach.
PYTHON
links = [elem['href'] for elem in soup.find_all('a', attrs = {'class': 'product-link'})]
names = [elem.get_text() for elem in soup.find_all('span', attrs = {'class': 'product-name'})]
prices = [elem.get_text() for elem in soup.find_all('span', attrs = {'data-content': 'product-price'})]
all_products_v2 = pd.DataFrame(
{'link': links, 'name': names, 'price': prices}
)The scraping pipeline
By now, you’ve learned the core tools for web scraping: requests, BeautifulSoup, and Selenium. Together, these tools form a powerful and flexible pipeline that can handle most scraping tasks. When starting a new scraping project, following a few key steps will help ensure you capture the data you need efficiently and responsibly.
The first step is to understand the structure of the website. Every site organizes its content differently, so take time to explore the page, inspect elements, and identify the HTML tags and attributes that hold the information you’re after.
Next, determine whether the content is static or dynamic. Static content is part of the initial HTML and can be accessed directly using requests and parsed with BeautifulSoup. Dynamic content, on the other hand, is loaded or updated by JavaScript after the initial page load, and typically requires Selenium to render the page fully before parsing.
Once you’ve identified how the content is delivered, build
your scraping pipeline. For static content, make a request
using requests.get() and pass the HTML to BeautifulSoup to
locate and extract the relevant elements. For dynamic pages, use
Selenium to open the page in a browser, interact with the page as needed
(e.g., clicking buttons, selecting dropdowns), and retrieve the updated
HTML with driver.page_source. Then use BeautifulSoup to
parse and extract the data.
Finally, clean, format, and store the data in a structured format, such as a list of dictionaries or a Pandas DataFrame, so it’s ready for analysis or export.
Following this pipeline helps you break down complex tasks into clear, manageable steps and choose the right tools for the job With practice, you’ll be able to adapt this process to scrape and organize data from a wide range of websites.
- Dynamic websites load content using JavaScript, so the data may not be present in the initial HTML. It’s important to distinguish between static and dynamic content when planning your scraping approach.
- The
Seleniumpackage and itswebdrivermodule simulates a real browser, allowing you to execute JavaScript and interact with the page as a user would —clicking, scrolling, or filling out forms - Key Selenium commands:
-
webdriver.Chrome(): Launch the Chrome browser simulator -
.get("website_url"): Visit a given website -
.find_element(by, value)and.find_elements(by, value): Locate one or multiple elements -
.click(): Click a selected element -
.page_source: Retrieve the full HTML after JavaScript execution -
.quit(): Close the browser
-
- The browser’s “Inspect” tool allows users to view the HTML document after dynamic content has loaded. This is useful for identifying which elements contain the data you want to scrape.
- A typical web scraping pipeline includes: 1) Understanding the website structure; 2) Determining whether content is static or dynamic; 3) Choosing the right tools (requests + BeautifulSoup or Selenium); 4) Extracting and cleaning the data; 5) Storing the data in a structured format.